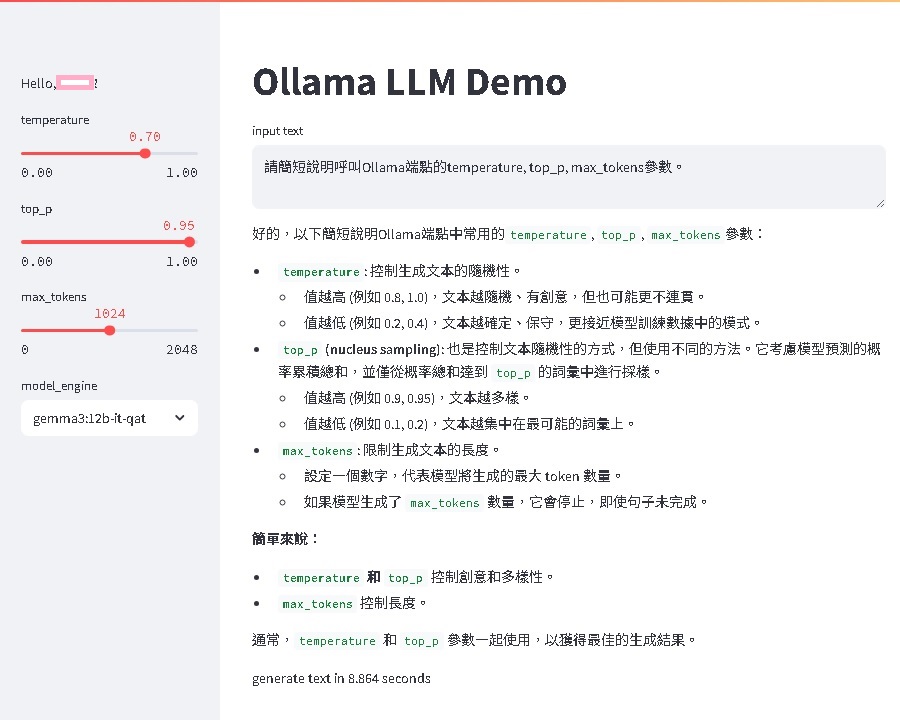
Ollama 提供端點串接服務,可由程式管理及使用本地大語言模型(LLM, Large Language Model)。 以下程式碼展示如何以 Streamlit 套件,建立一個輕量級的網頁介面,供呼叫本地端安裝的 Ollama 大語言模型。 Ollama 預設的服務端點為 http://localhost:11434。 使用者透過簡單的網頁操作,即可輸入提示詞(prompt),即時獲得模型回應。 此應用支援模型選擇、選字機率均化溫度(temperature)、選字累加機率門檻值(top_p)、問答最大符號數(max_tokens)等參數調整,並允許限定特定使用者(如 "john")。 Ollama Streamlit為一個實用的範例,適合想要快速整合本地 LLM ,建立互動式介面的開發者。
######################################
# ollama_client_streamlit.py
# an streamlit client to call ollama LLMs.
#
# # python 3.7.7 above recommended
# > conda activate your_streamlit_environment
# > streamlit run ollama_client_streamlit.py --server.port 8080
#
# http://localhost:8080?name=john
#
# Reference:
# GitHub: Ollama API Documentation
#
import streamlit as st
import requests
import time
import json
###################################
# Parameters for the Streamlit App
baseurl = 'http://localhost:11434'
generate_url = baseurl + '/api/generate'
tags_url = baseurl + '/api/tags'
# only names in pass_list are allowed to use LLM
pass_name_list = ["john"]
default_prompt = 'Where is the capital of Japan?'
# api_key is optional for endpoints with bearer authentication
api_key = ''
# returns a list of llm names installed in ollama
def get_ollama_models():
"""Fetches available models from the Ollama API and returns a list."""
##url = "http://localhost:11434/api/tags" # Ollama API endpoint
try:
headers={'Authorization': f'Bearer {api_key}'}
response = requests.get(tags_url, headers=headers)
# Raises an error for HTTP failures
response.raise_for_status()
data = response.json()
# Extract model names
return [model["name"] for model in data.get("models", [])]
except requests.exceptions.RequestException as e:
print(f"Error fetching models: {e}")
return []
# Calls /api/generate to request LLM in stream=true mode
# model: ollama installed llm
# temperature: 0 ~ 1 (decide how creative the answer is generated)
# top_p: 0 ~ 1 (decide how many most probable words to select)
# max_tokens: 0 ~ 2048 tokens
def generate_stream(prompt, model, temperature=0.7, top_p=0.95, max_tokens=1024):
args = {
'prompt': prompt,
'model': model,
'options': {
'temperature': temperature,
'top_p': top_p,
'max_tokens': max_tokens},
'stream': True
}
headers = {'Authorization': f'Bearer {api_key}'}
r = requests.post(generate_url, headers=headers, json=args, stream=True)
if r.status_code == 200:
# {"model":"gemma3:12b-it-qat",
# "created_at":"2025-05-24T09:18:43.944815912Z",
# "response":"The","done":false}
# print("Request successful!")
# with requests.post(url, headers=headers,
# data=json.dumps(data), stream=True) as response:
for line in r.iter_lines():
if line:
try:
chunk = json.loads(line.decode("utf-8"))
message = chunk.get("response", {})
# print(message)
yield message
except json.JSONDecodeError:
continue
# message = r.json()['response']
else:
message = f"Error: {r.status_code}, Message: {r.text}"
# response_json = response.json()
# message = response_json['response']
yield message
# no cache resource is needed with ollama endpoints
@st.cache_resource
def _load():
return
# calls generate_stream() to collect stream chunk response
# in _result.markdown(full_response)
@st.cache_data(ttl='1d') # cache _result for one day
def _generate(prompt, model, temperature=0.7, top_p=0.95, max_tokens=1024):
_result = st.empty()
full_response = ''
start = time.time()
for chunk in generate_stream(prompt, model, temperature, top_p, max_tokens):
full_response += chunk
_result.markdown(full_response)
# st.write_stream(response)
end = time.time()
st.write(f"generate text in {end - start:.3f} seconds\n\n")
# return response_placeholder
start = time.time()
_load()
end = time.time()
#############
# filter user
# only names in pass_name_list are allowed to use the app
params = st.query_params
name = params.get("name", "")
if name in pass_name_list:
result = f"Hello, {name}!"
else:
#result = "Unsupported user"
st.write(f"Sorry, you are not supported user.")
exit(0)
###############
# Streamlit UI
st.sidebar.write(f"Hello, {name}!")
# title for the web page
st.title("Ollama LLM Demo ")
# let sliders be located in left hand side of ui
# slider for temperature
temperature = st.sidebar.slider("temperature", 0.0, 1.0, 0.7, 0.01)
# slider for top_p
top_p = st.sidebar.slider("top_p", 0.0, 1.0, 0.95, 0.01)
# slider for max_tokens
max_tokens = st.sidebar.slider("max_tokens", 0, 2048, 1024, 1)
# selectbox for model_engine
models = get_ollama_models()
#print(models) # ["llama3.1", "gemma3:12b-it-qat"]
model_engine = st.sidebar.selectbox("model_engine", models)
# input text
prompt = st.text_area("Your Query for LLM", default_prompt)
# output area
_generate(prompt, model_engine, temperature, top_p, max_tokens)
沒有留言:
張貼留言