在檔案系統中,常有不同路徑指向相同檔案物件(包含檔案或目錄)之需要。
Windows 檔案系統過去提供捷徑檔(.lnk),供檔案總案或部份應用程式取用不同路徑之檔案物件。
Windows Vista 之後開始模仿 Unix 提供符號連結,允許檔案系統層級提供如下四種連結。
SYMLINK, SYMLINKD, JUNCTION, HardLink
0.捷徑連結: 以特殊捷徑檔(.lnk)供特殊有支援應用程式取用,由client application解析
DOS DIR 顯示 .lnk 副檔名
[註] 此 .lnk 於網芳分享他機時,他機可能無法使用
[註] del .lnk 可刪除捷徑,連結物件仍在
1.檔案符號連結: 預設安全原則需管理權限,連結可以跨切割,由client filesystem解析
Windows指令: mklink file_soft_link file
Unix指令: link -s file_soft_link file
DOS DIR 顯示 <SYMLINK>
[註] 此 file_soft_link 於網芳分享他機時,他機可能無法使用
[註] del file_soft_link 可刪除符號連結,連結檔案仍在
2.目錄符號連結: 預設安全原則需管理權限,連結可以跨切割,由client filesystem解析
Windows指令: mklink /d dir_soft_link dir
Unix指令: link -s dir_soft_link dir
DOS DIR 顯示 <SYMLINKD>
[註] 此 dir_soft_link 於網芳分享他機時,他機可能無法使用
[註] rmdir dir_soft_link 可刪除符號連結,連結目錄仍在
[註] del dir_soft_link 會詢問是否刪除目錄所有內容
3.目錄連結: 不需權限,連結限定本機任意切割,由server filesystem解析
Windows指令: mklink /j dir_hard_link dir
Unix指令: 無類似 unix 指令
DOS DIR 顯示 <JUNCTION>
[註] 此 dir_hard_link 於網芳分享他機時,他機仍可使用
[註] rmdir dir_hard_link 可刪除連結,連結目錄仍在
[註] del dir_hard_link 會詢問是否刪除目錄所有內容
4.檔案連結: 不需權限,連結限定本機本切割,由server filesystem解析
Windows指令: mklink /h file_hard_link file
Unix指令: link file_hard_link file
DOS DIR 顯示 等同普通檔案,無任何標示
[註] 此 file_hard_link 於網芳分享他機時,他機仍可使用
[註] del file_hard_link 可刪除連結,若連結檔案已無其他連結,檔案將真正刪除
註: 預設安全原則之下 mklink, mklink/d 兩個建立符號連結指令需管理權限,要以系統管理員執行DOS視窗,才能使用。
windows mklink vs unix link
weka.classifiers.misc.HyperPipes
weka.classifiers.misc.HyperPipes 屬類別屬性區間學習器,
記錄符合類別的屬性出現區間,再預測屬性符合比例高之類別,可提供案例集基本表現值供標竿比較之用。
HyperPipes 學習分類時,為每個類別建立一個超區間(hyperpipe),記錄每個屬性有出現該類別的案例區間為何。
預測分類時,計算新案例符合各類別的超區間程度,取符合程度高者為其預測類別。
案例符合某類別超區間程度(0~1)乃案例有多少比例(介於0~100%)的屬性落於某類別超區間的屬性描述區間內。
> java -cp weka.jar;. weka.classifiers.misc.HyperPipes -t data\weather.numeric.arff
HyperPipes classifier
HyperPipe for class: yes
temperature: 64.0,83.0,
humidity: 65.0,96.0,
outlook: true,true,true,
windy: true,true,
HyperPipe for class: no
temperature: 65.0,85.0,
humidity: 70.0,95.0,
outlook: true,false,true,
windy: true,true,
Time taken to build model: 0 seconds
Time taken to test model on training data: 0 seconds
=== Error on training data ===
Correctly Classified Instances 10 71.4286 %
Incorrectly Classified Instances 4 28.5714 %
Kappa statistic 0.2432
Mean absolute error 0.4531
Root mean squared error 0.4597
Relative absolute error 97.5824 %
Root relative squared error 95.8699 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
4 1 | b = no
=== Stratified cross-validation ===
Correctly Classified Instances 9 64.2857 %
Incorrectly Classified Instances 5 35.7143 %
Kappa statistic 0
Mean absolute error 0.483
Root mean squared error 0.4899
Relative absolute error 101.4286 %
Root relative squared error 99.3055 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
5 0 | b = no
如下 weather.numeric.arff 案例集的14個案例有9個yes,5個no。
| outlook | temperature | humidity | windy | play |
| sunny | 85 | 85 | FALSE | no |
| sunny | 80 | 90 | TRUE | no |
| rainy | 65 | 70 | TRUE | no |
| sunny | 72 | 95 | FALSE | no |
| rainy | 71 | 91 | TRUE | no |
| overcast | 83 | 86 | FALSE | yes |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 68 | 80 | FALSE | yes |
| overcast | 64 | 65 | TRUE | yes |
| sunny | 69 | 70 | FALSE | yes |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
| overcast | 72 | 90 | TRUE | yes |
| overcast | 81 | 75 | FALSE | yes |
weka.classifiers.rules.OneR
weka.classifiers.rules.OneR 屬單節點決策樹(單屬性規則)學習器,
利用單屬性多數/區間多數決原理,提供案例集基本表現值供標竿比較之用。
任何學習器都應該比OneR基本表現更好才有存在價值。
OneR學習分類時,為每個屬性建立一顆單節點決策樹,最後留下錯誤率最低者。
預測時則只根據留下的單節點決策樹,依單一屬性值的多數/區間多數決作為預測類別。
參數說明:
-B 數值屬性的區間(bucket)切割參數,預設值6,
表示任一區間要成立,其多數決類別必需擁有的最少案例數。
此下限值愈低,愈容易出現小區間,遷就案例能力愈強。
> java -cp weka.jar;. weka.classifiers.rules.OneR -t data\weather.numeric.arff
outlook:
sunny -> no
overcast -> yes
rainy -> yes
(10/14 instances correct)
Time taken to build model: 0.01 seconds
Time taken to test model on training data: 0 seconds
=== Error on training data ===
Correctly Classified Instances 10 71.4286 %
Incorrectly Classified Instances 4 28.5714 %
Kappa statistic 0.3778
Mean absolute error 0.2857
Root mean squared error 0.5345
Relative absolute error 61.5385 %
Root relative squared error 111.4773 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
7 2 | a = yes
2 3 | b = no
=== Stratified cross-validation ===
Correctly Classified Instances 6 42.8571 %
Incorrectly Classified Instances 8 57.1429 %
Kappa statistic -0.2444
Mean absolute error 0.5714
Root mean squared error 0.7559
Relative absolute error 120 %
Root relative squared error 153.2194 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
5 4 | a = yes
4 1 | b = no
如下weather.numeric.arff 案例集的4個屬性,以outlook所建單節點決策樹錯誤率最低
| outlook | temperature | humidity | windy | play |
| overcast | 83 | 86 | FALSE | yes |
| overcast | 64 | 65 | TRUE | yes |
| overcast | 72 | 90 | TRUE | yes |
| overcast | 81 | 75 | FALSE | yes |
| rainy | 65 | 70 | TRUE | no |
| rainy | 71 | 91 | TRUE | no |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 68 | 80 | FALSE | yes |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 85 | 85 | FALSE | no |
| sunny | 80 | 90 | TRUE | no |
| sunny | 72 | 95 | FALSE | no |
| sunny | 69 | 70 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
OneR 針對數值屬性提供區間(bucket)切割參數-B,預設值6,
表示任一區間要成立,其多數決類別必需擁有至少 6 個案例數。此下限值愈低,愈容易出現小區間,遷就案例能力愈強。
> java -cp weka.jar;. weka.classifiers.rules.OneR -t data\weather.numeric.arff -B 1
Options: -B 1
temperature:
< 64.5 -> yes
< 66.5 -> no
< 70.5 -> yes
< 71.5 -> no
< 77.5 -> yes
< 80.5 -> no
< 84.0 -> yes
>= 84.0 -> no
(13/14 instances correct)
Time taken to build model: 0.01 seconds
Time taken to test model on training data: 0 seconds
=== Error on training data ===
Correctly Classified Instances 13 92.8571 %
Incorrectly Classified Instances 1 7.1429 %
Kappa statistic 0.8372
Mean absolute error 0.0714
Root mean squared error 0.2673
Relative absolute error 15.3846 %
Root relative squared error 55.7386 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
1 4 | b = no
=== Stratified cross-validation ===
Correctly Classified Instances 5 35.7143 %
Incorrectly Classified Instances 9 64.2857 %
Kappa statistic -0.3404
Mean absolute error 0.6429
Root mean squared error 0.8018
Relative absolute error 135 %
Root relative squared error 162.5137 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
4 5 | a = yes
4 1 | b = no
如下weather.numeric.arff 案例集的4個屬性,以temperature所建單節點決策樹錯誤率雖低,
只是遷就看過資料能力強,預測未見資料能力則弱。
| outlook | temperature | humidity | windy | play |
| overcast | 64 | 65 | TRUE | yes |
| rainy | 65 | 70 | TRUE | no |
| rainy | 68 | 80 | FALSE | yes |
| sunny | 69 | 70 | FALSE | yes |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 71 | 91 | TRUE | no |
| overcast | 72 | 90 | TRUE | yes |
| sunny | 72 | 95 | FALSE | no |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
| sunny | 80 | 90 | TRUE | no |
| overcast | 81 | 75 | FALSE | yes |
| overcast | 83 | 86 | FALSE | yes |
| sunny | 85 | 85 | FALSE | no |
weka.classifiers.rules.ZeroR
weka.classifiers.rules.ZeroR屬背景值(零規則)學習器,利用多數/平均決原理,提供案例集背景表現值供標竿比較之用。
任何學習器都應該比ZeroR表現(背景值)更好才有存在價值。
ZeroR學習分類時只記錄看過案例中多數類別為何。學習迴歸時只記錄看過案例的平均值為何。
預測時則完全不看案例屬性,任何案例的分類皆預測為記錄的多數類別,任何迴歸皆預測為記錄的平均值。
> java -cp weka.jar;. weka.classifiers.rules.ZeroR -t data\weather.numeric.arff
ZeroR predicts class value: yes
Time taken to build model: 0 seconds
Time taken to test model on training data: 0 seconds
=== Error on training data ===
Correctly Classified Instances 9 64.2857 %
Incorrectly Classified Instances 5 35.7143 %
Kappa statistic 0
Mean absolute error 0.4643
Root mean squared error 0.4795
Relative absolute error 100 %
Root relative squared error 100 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
5 0 | b = no
=== Stratified cross-validation ===
Correctly Classified Instances 9 64.2857 %
Incorrectly Classified Instances 5 35.7143 %
Kappa statistic 0
Mean absolute error 0.4762
Root mean squared error 0.4934
Relative absolute error 100 %
Root relative squared error 100 %
Total Number of Instances 14
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
5 0 | b = no
如下 weather.numeric.arff 案例集的14個案例有9個yes,5個no。
| outlook | temperature | humidity | windy | play |
| sunny | 85 | 85 | FALSE | no |
| sunny | 80 | 90 | TRUE | no |
| rainy | 65 | 70 | TRUE | no |
| sunny | 72 | 95 | FALSE | no |
| rainy | 71 | 91 | TRUE | no |
| overcast | 83 | 86 | FALSE | yes |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 68 | 80 | FALSE | yes |
| overcast | 64 | 65 | TRUE | yes |
| sunny | 69 | 70 | FALSE | yes |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
| overcast | 72 | 90 | TRUE | yes |
| overcast | 81 | 75 | FALSE | yes |
Java Certification for Undergraduates
Java證照準備資訊:
Java證照簡單分為三級: 入門,專業,大師。 入門及專業級皆考選擇題,大師級才實際考程式實作. 入門級建議升大三暑假,專業級建議升大四暑假,大師級則工作前後再考. Oracle Java Certifications (甲骨文Java證照) Associate Level Certification (入門) Java SE 5 and 6, Certified Associate 1Z0-850 (原SCJA) http://education.oracle.com/pls/web_prod-plq-dad/db_pages.getpage?page_id=652&get_params=p_exam_id:1Z0-850 考Java基礎知識(UML,物件觀念等),115分鐘,51選擇題,68%(35題)以上通過,TWD4934 Java SE 7 Programmer I 1Z0-803 Java SE 8 Programmer I 1Z0-808 Professional Level Cerfification (專業) Java SE 5 Programmer Certified Professional 1Z0-853 Java SE 6 Programmer Certified Professional 1Z0-851 (原SCJP) http://education.oracle.com/pls/web_prod-plq-dad/db_pages.getpage?page_id=652&get_params=p_exam_id:1Z0-851 考Java程式語法及標準類別庫,150分鐘,60選擇題,61%(37題)以上通過,TWD4934 Java SE 7 Programmer II 1Z0-804 Java SE 8 Programmer II 1Z0-809 Master Level Cerfification (大師) Java SE 6 Developer Certified Master Assignment 1Z0-855 http://education.oracle.com/pls/web_prod-plq-dad/db_pages.getpage?page_id=652&get_params=p_exam_id:1Z0-855 考Java程式開發含前後台及資料庫,買實作題後6個月內繳交+120分鐘申論題,視表現決定通過,TWD4934 PS:相關OCJ認證說明: http://www.whizlabs.com/oracle-java-certifications/ http://www.codedata.com.tw/book/java-basic/certification.php
mahout training set for irstats
https://github.com/apache/mahout/blob/master/mrlegacy/src/main/java/org/apache/mahout/cf/taste/GenericRecommenderIRStatsEvaluator.java
130~134行用意在從原始資料集dataModel,
// 建立一個空的喜好容器,容量為資料集所有用戶數,當成初始訓練集trainingUsers
FastByIDMap trainingUsers = new FastByIDMap(dataModel.
LongPrimitiveIterator it2 = dataModel.getUserIDs(); // 取得資料集所有用戶之列舉器
while (it2.hasNext())
{
// 就每一列舉用戶it2.nextLong(),從資料集dataModel依下法適當取得喜好,加入訓練集trainingUsers
// 若遇userID用戶,就只取其所有資料集喜好,扣掉標準答案relevantItemIDs,加入訓練集;
// 若遇其他用戶,則取其所有資料集喜好,直接加入訓練集;
// 詳https://github.com/apache/
dataSplitter.processOtherUser(
}
130~134行用意在從原始資料集dataModel,
// 建立一個空的喜好容器,容量為資料集所有用戶數,當成初始訓練集trainingUsers
FastByIDMap
LongPrimitiveIterator it2 = dataModel.getUserIDs(); // 取得資料集所有用戶之列舉器
// 若遇userID用戶,就只取其所有資料集喜好,扣掉標準答案relevantItemIDs,加入訓練集;
// 若遇其他用戶,則取其所有資料集喜好,直接加入訓練集;
// 詳https://github.com/apache/
}
何謂常數
Java允許程式中有常數存在,通常用來運算或令值給變數.
常數顧名思義就是一個不會變動的值.
常數也有型別,常見的常數型別如下:
1.物件類: 就只有空物件常數null
2.布林類: 就只有真假兩常數true,false
3.數字類: 分成整數及浮點兩類,
3A.整數類: 凡是沒有小數點的數字一律當成int型別
若想視為long型別,可在整數後加L.
3B.浮點類: 凡是有小數點的數字一律當成double型別
若想視為float型別,可在浮點後加F.
10的多少次方可用E後面加數字表示.
4.文字類: 分成字元及字串兩類,
4A.字元類: 凡是單引號夾的字元,一律當成char型別
4B.字串類: 凡是雙引號夾的字串,一律當成String型別
舉例:
Scanner sc = null; // 令sc值為空物件null
boolean b=false; // 令b值為boolean常數假
int i = 0; // 令i值為int常數0
long l = 0L; // 令l值為long常數0
double d = 1.23e2; // 令d值為double常數1.23*10^2,即實數123
float f = 0.0F; // 令f值為float常數0
char c = 'A'; // 令c值為char常數A
char c2 = '好'; // 令c2值為char常數好
char c3 = '\u000d'; // 令c3值為char常數Unicode字碼\u000d,即換行字元\n
String s = null; // 令s值為空物件null,字串也屬物件,故可填入空物件值
String s2 = ""; // 令s2值為String常數空字串
String s3 = "今天天氣很好\n"; // 令s3值為String常數今天天氣很好\n
數字類常數在令值給變數時,
若遇常數值放不進變數型別範圍,或大範圍型別放入小範圍型別,
則會出現error: possible loss of precision可能丟失精準度錯誤,
這時要使用強制轉型指令,常數前加(欲轉型型別名),才能編譯過關.
舉例:
double d = 3; // int小範圍型別放入double大範圍型別,沒問題
float f = 3; // int小範圍型別放入float大範圍型別,沒問題
long l = 3; // int小範圍型別放入long大範圍型別,沒問題
int i = 3; // int型別放入int同型別,沒問題
short s = 3; // int大範圍型別放入short小範圍型別,本有問題,但值3本身放得進short,故無問題
byte b = 3; // int大範圍型別放入byte小範圍型別,本有問題,但值3本身放得進byte,故無問題
double d2 = 3.0; // double型別放入double同型別,沒問題
float f2 = 3.0; // 有丟失精準度錯誤, 3.0常數視為double型別,不能放入較小範圍float型別內
float f2 = (float) 3.0; // double強制轉型為float,再令值就沒問題
int i2 = 3.0; // 有丟失精準度錯誤, 3.0常數視為double型別,不能放入較小範圍int型別內
int i3 = (int) 3.0; // double強制轉型為int,再令值就沒問題
PS
1. 數字類型別範圍,由小到大,如下: (可參考課本附錄D基本型別介紹)
byte: 8bits: -2^7=-128 ~ 127=2^7-1
short: 16bits: -2^15=-32768 ~ 32767=2^15-1
int: 32bits: -2^31=-2e9 ~ 2e9=2^31-1
long: 64bits: -2^63=-9e18 ~ 9e18=2^63-1
float: 32bits: -3.4e38 ~ -1.4e-45, 0, 1.4e-45 ~ 3.4e38
double: 64bits: -1.7e308 ~ -4.9e-324, 0, 4.9e-324 ~ 1.7e308
2. 中英對照
常數 constant, literal
單引號 single quote
雙引號 double quote
強制轉型 type casting
簡單if區塊
指令是程式最基本組成單元,其特徵是每道指令必有一個分號 ; 作結束,
因此,要數程式有幾道指令,最簡單方法就是數有幾個分號。
指令中最簡單就屬空指令,即單獨一個分號,前面不寫任何東西。
程式若遇空指令則不作事,直接跳到下一道指令執行。
又許多指令可以合併成一個區塊,其特徵是每個區塊必有一組大括號 {} 包夾起來。
區塊內可以放置眾多指令,供依序執行之用。
最簡單的區塊不外乎空區塊,內含0個指令,其作用和空指令相當,不作事。
次簡單的區塊則為單指令區塊,只含一個指令。
語法上,單指令區塊,其包夾之大括號皆可省略,
但初學者宜留著大括號,以方便區塊結構之辨識。
一個區塊的地位等同於一道指令,凡可以放置指令的地方都可以放置區塊,
因此,區塊內除了放置指令,也可以放置區塊,形成多層區塊包夾情形。
程式正常是一道一道指令循序執行,若將每道指令視為單指令區塊,
則程式也可看成是一個一個區塊循序執行。
如果在循序執行過程,希望有某區塊能依情況略過不執行,
這時簡單if區塊就可以派上用場,其結構如下,
if(條件)
{
// 此處放置條件成立情況下想執行之區塊指令
}
其中,if區塊最前面的條件可決定該區塊要不要執行,有點像流程轉向控制開關。
條件可放置任何能算出真或假值的邏輯運算式,
若條件得到真,則區塊會進入執行;
若得到假,則略過區塊,跳到下一指令或區塊執行。
舉例: 假設scanner為初始化之掃瞄器物件。
int x;
x=scanner.nextInt(); // cin >> x;
if(x>5)
{
System.out.printf("x:%d > 5\n", x); // cout << "x:" << x << ">5" << endl;
}
System.out.printf("x:%d\n", x); // cout << "x:" << x << endl;
以上程式碼以區塊觀點共分成4區塊,
第1區塊宣告配置整數變數x指令,
第2區塊為x由掃瞄器物件給初值指令,
第3區塊為if區塊,含列印x>5指令,
但區塊執不執行由條件x>5為真否決定,
第4區塊為列印x值指令。
循序執行4區塊結果,於第2區塊接收x值後,
若x值大於5,則x>5條件成立,會進入第3的if區塊印x>5;
若x值小於等於5,則x>5條件不成立,會略過第3的if區塊不印x>5;
但不管印不印x>5,最後都會到第4區塊印x值。
可見簡單if區塊的用途適合在選擇性決定要不要多作事的情況。
選擇的依據就是區塊前的給定條件,多作事的內容則記錄在區塊內。
至於為何稱為簡單if區塊結構?
理由是以後還有完整if區塊結構,除了原來成立要執行的if區塊,
還有不成立要執行的else區塊,算是簡單if區塊的擴充完整版。
PS: 中英對照
分號 semicolon
大括號 brace
指令 statement
區塊 block
空指令 null statement
空區塊 null block
包夾 enclose
條件 condition
邏輯運算式 logical expression
循序執行 sequential execution
單指令區塊 single-statement block
簡單if區塊 simple if-block
完整if區塊 complete if-block
結構 construct,structure
數字系統轉換學習順序
2,8,10,16進位的正整數之間如何轉換,
建議依如下順序作練習:
0.10轉2: 練習8位元0~255十進位數字,利用成份法轉換成2進位數字.
1.10轉2,8,16: 以10進位數字為中心,利用長除法轉換成其他2,8,16進位數字,
2.2,8,16轉10: 將其他2,8,16進位數字,利用次方法還原成10進位數字.
3.2轉8,16: 將2進位數字用快速分組法轉換成8,16進位數字.
4.8,16轉2: 將8,16進位數字用快速攤開法轉換成2進位數字.
5.8轉16: 將8進位數字用攤開+分組法轉換成16進位數字
6.16轉8: 將16進位數字用攤開+分組法轉換成8進位數字
註: 算出任何結果皆宜反向驗證,確認還原數字相同否.
0.8位元2進位成份法:
挑選適當128,64,32,16,8,4,2,1共8位元加回原來10進位數字.
挑中位元其位置為1;未挑中位元其位置為0
1.長除法: 可將10進位數字轉換成n進位數字
不斷利用除以n動作,留下餘數,直到原數除到商為0,
依序將先留餘數放在最低數元,最後餘數在最高數元.
2.次方法: 可將n進位數字,還原成10位位數字
將n進位最低數元乘上n零次方,加上次低數元乘上n一次方,
加上次次低數元乘上n二次方,以此類推直到最高數元用完為止.
3.分組法: 2轉8,由低數元開始,每3數元一組,改寫成8進位數元
2轉16,由低數元開始,每4數元一組,改寫成16進位數元
4.攤開法: 8轉2,由低數元開始,每數元攤開成3個2進位數元
16轉2,由低數元開始,每數元攤開成4個2進位數元
5.任一個數字的低數元比較靠近右,高數元比較靠近左.
高數元: more significant radix
低數元: less significant radix
最低數元: 以整數來說,就是位在最右邊的個位數元
6.其他參考資料:
https://ilms.csu.edu.tw/sys/read_attach.php?id=264201
http://content.edu.tw/vocation/control/tp_nh/control/tp_nh/logic/ch2/p5.htm
http://www.ltivs.ilc.edu.tw/kocp/logic/ch2/2-2.htm
建議依如下順序作練習:
0.10轉2: 練習8位元0~255十進位數字,利用成份法轉換成2進位數字.
1.10轉2,8,16: 以10進位數字為中心,利用長除法轉換成其他2,8,16進位數字,
2.2,8,16轉10: 將其他2,8,16進位數字,利用次方法還原成10進位數字.
3.2轉8,16: 將2進位數字用快速分組法轉換成8,16進位數字.
4.8,16轉2: 將8,16進位數字用快速攤開法轉換成2進位數字.
5.8轉16: 將8進位數字用攤開+分組法轉換成16進位數字
6.16轉8: 將16進位數字用攤開+分組法轉換成8進位數字
註: 算出任何結果皆宜反向驗證,確認還原數字相同否.
0.8位元2進位成份法:
挑選適當128,64,32,16,8,4,2,1共8位元加回原來10進位數字.
挑中位元其位置為1;未挑中位元其位置為0
1.長除法: 可將10進位數字轉換成n進位數字
不斷利用除以n動作,留下餘數,直到原數除到商為0,
依序將先留餘數放在最低數元,最後餘數在最高數元.
2.次方法: 可將n進位數字,還原成10位位數字
將n進位最低數元乘上n零次方,加上次低數元乘上n一次方,
加上次次低數元乘上n二次方,以此類推直到最高數元用完為止.
3.分組法: 2轉8,由低數元開始,每3數元一組,改寫成8進位數元
2轉16,由低數元開始,每4數元一組,改寫成16進位數元
4.攤開法: 8轉2,由低數元開始,每數元攤開成3個2進位數元
16轉2,由低數元開始,每數元攤開成4個2進位數元
5.任一個數字的低數元比較靠近右,高數元比較靠近左.
高數元: more significant radix
低數元: less significant radix
最低數元: 以整數來說,就是位在最右邊的個位數元
6.其他參考資料:
https://ilms.csu.edu.tw/sys/read_attach.php?id=264201
http://content.edu.tw/vocation/control/tp_nh/control/tp_nh/logic/ch2/p5.htm
http://www.ltivs.ilc.edu.tw/kocp/logic/ch2/2-2.htm
數字系統轉換: 10進位篇
在了解數字系統之前,先了解何謂數字。一個數字通常由很多數元組成,正確的講,是從左到右依序寫在高到低位置上的多個數元組成。至於數字有那些數元可用則和數字是幾進位的數字有關,例如常用10進位數字有0~9共10個數元可用,16進位數字有0~9A-F共16個數元可用,2進位數字則只有0,1兩個數元可用。其規則為b進位數字將有0~b-1共b個數元可用。習慣上,將所有b進位數字形成的集合稱為b進位數字系統或基數b數字系統,記作()b。一般數字若不作()b標記,預設為10進位數字。
由於每個數字皆可用不同基數的數字系統表示,如何讓數字在不同數字系統之間轉換遂成為一個困擾。以下將先介紹次方法公式,適用於b進位轉10進位情況。
(an-1…a2a1a0)b= an-1⋅bn-1 + … + a2⋅b2 + a1⋅b1 + a0⋅b0
其中,(an-1…a2a1a0)b表示某b進位數字,包含n個數元,數元由高到低位置分別為an-1到a0。
例1: 此公式之正確性可由10進位數字皆可依如下公式還原,而得到驗證。
(4567)10 = 4⋅103 + 5⋅102 + 6⋅101 + 7⋅100 = 4000 + 500 + 60 + 7 = 4567
例2: 如下8進位數字為何10進位數字
(4567)8 = (?)10
= 4⋅83 + 5⋅82 + 6⋅81 + 7⋅80 = 4⋅512 + 5⋅64 + 6⋅8 + 7⋅1= 2423 = (2423) 10
例3: 如下16進位數字為何10進位數字
(4567)16 = (?)10
= 4⋅163 + 5⋅162 + 6⋅161 + 7⋅160 = 4⋅4096 + 5⋅256 + 6⋅16 + 7⋅1
= 17767 = (17767) 10
例4: 如下2進位數字為何10進位數字
(1011)2 = (?)10
= 1⋅23 + 0⋅22 + 1⋅21 + 1⋅20 = 1⋅8 + 0⋅4+ 1⋅2 + 1⋅1 = 11 = (11)10
接下來介紹長除法公式,適用於10進位轉b進位之反方向情況。假設10進位數字x想轉為b進位數字(an-1…a2a1a0)b,則各數元ai計算法如下。
x ÷ b = x0 = (an-1…a2a1)b … a0
x0 ÷ b = x1= (an-1…a2)b … a1
…
xn-2 ÷ b = xn-1= 0 … an-1
其中,先求得餘數放在低數元,後求得餘數放在高數元,直到商變0為止。
例4: 同樣此公式之正確性可由10進位數字皆可依如下公式還原,而得到驗證。
4567 ÷ 10 = 456 … 7
456 ÷ 10 = 45 … 6
45 ÷ 10 = 4 … 5
4 ÷ 10 = 0 … 4
故得4567 = (4567)10
其實若將4567想成4⋅103 + 5⋅102 + 6⋅101 + 7⋅100=(((0+4)⋅10+5)⋅10+6)⋅10+7就可理解為何長除法求得餘數要先放低數元位置,再逐一放到高數元位置原因。
例2: 如下10進位數字為何8進位數字
(2423)10 = (?)8
2423 ÷ 8 = 302 … 7
302 ÷ 8 = 37 … 6
37 ÷ 8 = 4 … 5
4 ÷ 8 = 0 … 4
故得(2423)10 = (4567)8
例3: 如下10進位數字為何16進位數字
(17767)10 = (?)16
17767 ÷ 16 = 1110 … 7
1110 ÷ 16 = 69 … 6
69 ÷ 16 = 4 … 5
4 ÷ 16 = 0 … 4
故得(17767)10 = (4567)16
例4: 如下10進位數字為何2進位數字
(11)10 = (?)2
11 ÷ 2 = 5 … 1
5 ÷ 2 = 2 … 1
2 ÷ 2 = 1 … 0
1 ÷ 2 = 0 … 1
故得(11)10 = (1011)2
以上介紹了b轉10的次方法及10轉b的長除法後,理論上任何兩數字系統皆可經由10進位數字系統而作轉換。例如:8轉16可先8轉10,再10轉16即得。
PS:中英對照
數字 number
數元 radix
數字系統 number system
基數 base
商 quotient
餘數 remainder
高數元位置 more significant radix position
低數元位置 less significant radix position
2進位 binary
8進位 octal
10進位 decimal
16進位 hexadecimal
n進位 base n
長除法 long division method
次方法 power method
訂閱:
文章 (Atom)
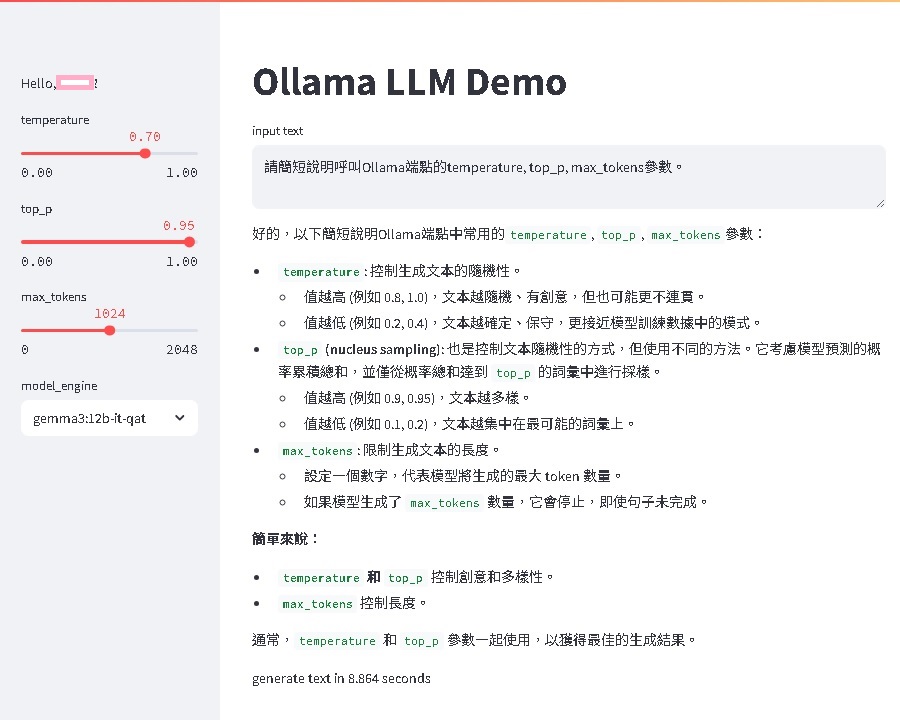
Building a Lightweight Streamlit Client for Local Ollama LLM Interaction
Ollama 提供端點串接服務,可由程式管理及使用本地大語言模型(LLM, Large Language Model)。 以下程式碼展示如何以 Streamlit 套件,建立一個輕量級的網頁介面,供呼叫 本地端安裝的 Ollama 大語言模型。 Ollama 預設的服務...