weka.classifiers.bayes.NaiveBayesSimple 為簡單貝氏機率學習器的簡化版,
記錄各類別事前機率,及給定類別下各屬性值出現之條件機率,
再依案例,累乘得到給定屬性值下各類別出現之事後機率,取機率高者為預測類別,
可提供案例集不錯表現值供標竿比較之用。
NaiveBayesSimple 學習分類時,同樣為每個類別統計其類別事前機率(prior probability)、給定類別下各屬性值出現之條件機率。
遇數值屬性時,一律假設母體為常態分布,統計其平均值、標準差,供條件機率之推估。
預測分類時,依新案例,累乘得到給定屬性值下各類別出現之事後機率(posterior probability),取機率高者為預測類別。
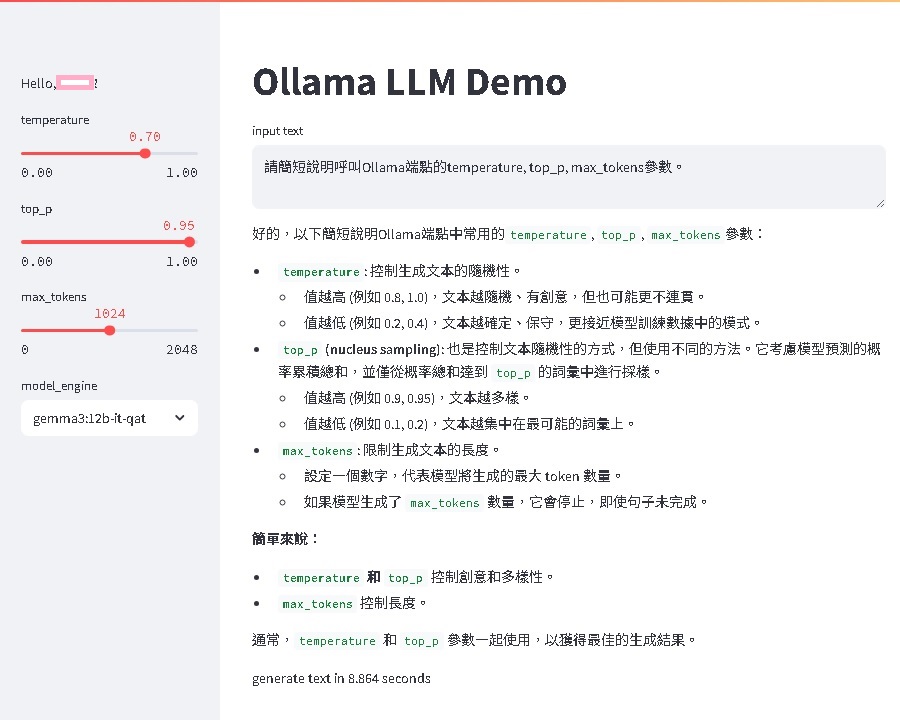
參數說明:
出處: R. Duda and P. Hart (1973). Pattern Classification and Scene Analysis. Wiley, New York.
>java -cp simpleEducationalLearningSchemes.jar;weka.jar;.
weka.classifiers.bayes.NaiveBayesSimple -t data\weather.numeric.arff
Naive Bayes (simple)
Class yes: P(C) = 0.625
Attribute outlook
sunny overcast rainy
0.25 0.41666667 0.33333333
Attribute temperature
Mean: 73 Standard Deviation: 6.164414
Attribute humidity
Mean: 79.11111111 Standard Deviation: 10.21572861
Attribute windy
TRUE FALSE
0.36363636 0.63636364
Class no: P(C) = 0.375
Attribute outlook
sunny overcast rainy
0.5 0.125 0.375
Attribute temperature
Mean: 74.6 Standard Deviation: 7.8930349
Attribute humidity
Mean: 86.2 Standard Deviation: 9.7313925
Attribute windy
TRUE FALSE
0.57142857 0.42857143
Time taken to build model: 0.77 seconds
Time taken to test model on training data: 0 seconds
=== Error on training data ===
Correctly Classified Instances 13 92.8571 %
Incorrectly Classified Instances 1 7.1429 %
Kappa statistic 0.8372
Mean absolute error 0.3003
Root mean squared error 0.3431
Relative absolute error 64.6705 %
Root relative squared error 71.5605 %
Total Number of Instances 14
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.200 0.900 1.000 0.947 0.849 0.933 0.963 yes
0.800 0.000 1.000 0.800 0.889 0.849 0.933 0.925 no
Weighted Avg. 0.929 0.129 0.936 0.929 0.926 0.849 0.933 0.949
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
1 4 | b = no
=== Stratified cross-validation ===
Correctly Classified Instances 8 57.1429 %
Incorrectly Classified Instances 6 42.8571 %
Kappa statistic -0.0244
Mean absolute error 0.4699
Root mean squared error 0.5376
Relative absolute error 98.6856 %
Root relative squared error 108.9683 %
Total Number of Instances 14
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.778 0.800 0.636 0.778 0.700 -0.026 0.444 0.636 yes
0.200 0.222 0.333 0.200 0.250 -0.026 0.444 0.398 no
Weighted Avg. 0.571 0.594 0.528 0.571 0.539 -0.026 0.444 0.551
=== Confusion Matrix ===
a b <-- classified as
7 2 | a = yes
4 1 | b = no
如下 weather.numeric.arff 案例集的14個案例利用2個文字屬性及2個數字屬性,預測文字屬性。
| outlook | temperature | humidity | windy | play |
| sunny | 85 | 85 | FALSE | no |
| sunny | 80 | 90 | TRUE | no |
| rainy | 65 | 70 | TRUE | no |
| sunny | 72 | 95 | FALSE | no |
| rainy | 71 | 91 | TRUE | no |
| overcast | 83 | 86 | FALSE | yes |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 68 | 80 | FALSE | yes |
| overcast | 64 | 65 | TRUE | yes |
| sunny | 69 | 70 | FALSE | yes |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
| overcast | 72 | 90 | TRUE | yes |
| overcast | 81 | 75 | FALSE | yes |
參考:
1.weka.classifiers.bayes.NaiveBayesSimple
code |
doc
2.從Weka 3.7.2版之後,NaiveBayesSimple 類別
從 weka.jar 主套件改歸到 simpleEducationalLearningSchemes.jar 選擇性套件內,
可利用Tools/Package Manager/Search: simpleEducationalSchemes/Install進行安裝。
在Windows下,下載套件存放位置在 C:\Users\用戶名\wekafiles\packages\ 資料夾內。
simpleEducationalSchemes 包含IB1,Prism,Id3,NaiveBayesSimple四個簡單分類器